SQL 进阶
我们都知道 select 的基本用法select <字段名> from <表名> [where <限制条件>],然而select语句后面还可以跟很多限制条件。我们这次用 user 表来作为示范,下面是 user 表的结构:
¶Between、And、In、<=、>=、<、> 等条件查询
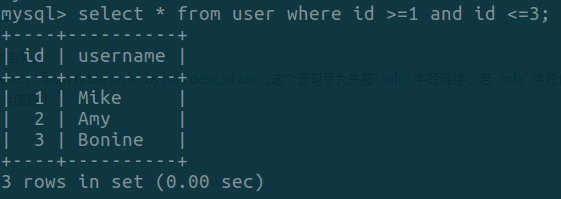
通过select * from table where id between 1 and 3和select * from table where id >=1 and id <= 3的返回结果,我们可以发现between and和>= and <=是等同的。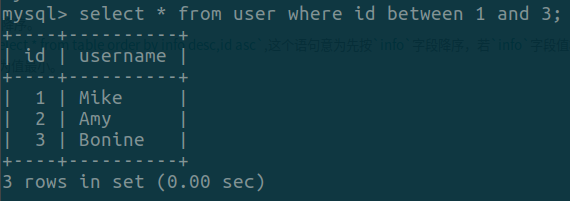
如果我们要查询的条件不是一个连续的数值,可以用in:
select * from table where id in (2,4)¶locate () 函数:locate(substr,str)
这个函数返回substr在字符串str中的第一个出现的位置,如果不存在则值为 0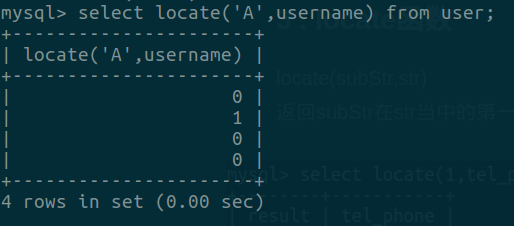
¶Count () 函数
count (字段名):返回指定列的值的数目,但是字段值为
NULL时不会被计算进去。select count(字段名) from <表名>count (*):返回表中的记录数,字段值为
NULL时会被计算进去。select count(*) from <表名>
¶Distinct 语句
Distinct 语句用于去除重复行,比如:select distinct * from <表名>。
其他的语句或函数都可以和distinct配合使用,比如:count(distinct <字段名>)可以去除重复行统计行数,但是count(distinct *)是不被允许的
¶Union 语句
Union 语句可以将两个select语句的结果集组合成一个:
(select * from table where id >= 3) union (select * from table where id = 1)当我们使用union语句的时候,默认去除了重复行,和distinct的效果一样,如果要显示所有的结果,则要使用union all语句。
¶Order by 语句
select * from table order by <字段名> [asc/desc]其中asc是默认的排序,为升序,desc为降序。
当然 order by 后面可以跟很多个字段,如:select * from table order by info desc,id asc,这个语句意为先按info字段降序,若info字段值相同的情况下,再按id字段升序。而且,NULL默认为值最小。
 wechat
wechat alipay
alipay
